Split and create relations
To keep our data organized, it's good practice to categorize our information into logical groups.
We want to keep independent entities separate
and create relations between them. This process is called normalisation.
Simply by the GUI (e.g. using buttons, dropdown menues and input/tick boxes), the Galaxy and Morphology data can be
structured into two separate tables (say MORPHOLOGY and GALAXY), as shown in Figures 5 to 7.
We now have created the relation between the tables, having the morphology
data independent to the galaxy data, and associating each galaxy to a specific morphology.
From Figures 5 and 6, we can see the relationship between MORPHOLOGY and GALAXY
is built on the attribute morphologyNo. This was made possible by setting up the
"Foreign Key" during the creation of the table GALAXY with MORPHOLOGY(morphologyNo).
Therefore, when we will want to insert a new galaxy along with its morphology,
we will get an error if we do not provide a valid morphologyNo.
In other word, the insertion won't happen if we want to assign a morphology that doesn't exist.
Extra information about PRIMARY KEY.
By default, DB Browser displayed the menus in French on my machine. Don't you worry, it should be in your langage on your machine!
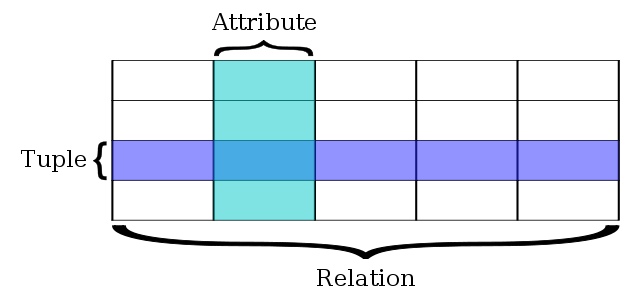 Figure 1. A simple relational database (source: wikipedia).
Figure 1. A simple relational database (source: wikipedia).
 Figure 2.
Figure 2.  Figure 3.
Figure 3. 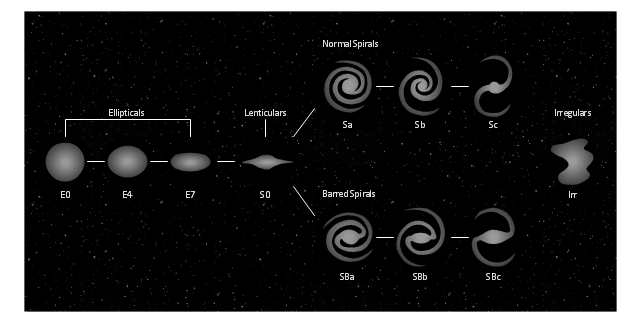 Figure 4. (Outdated) Hubble Classification of Galaxy Morphology.
Figure 4. (Outdated) Hubble Classification of Galaxy Morphology.
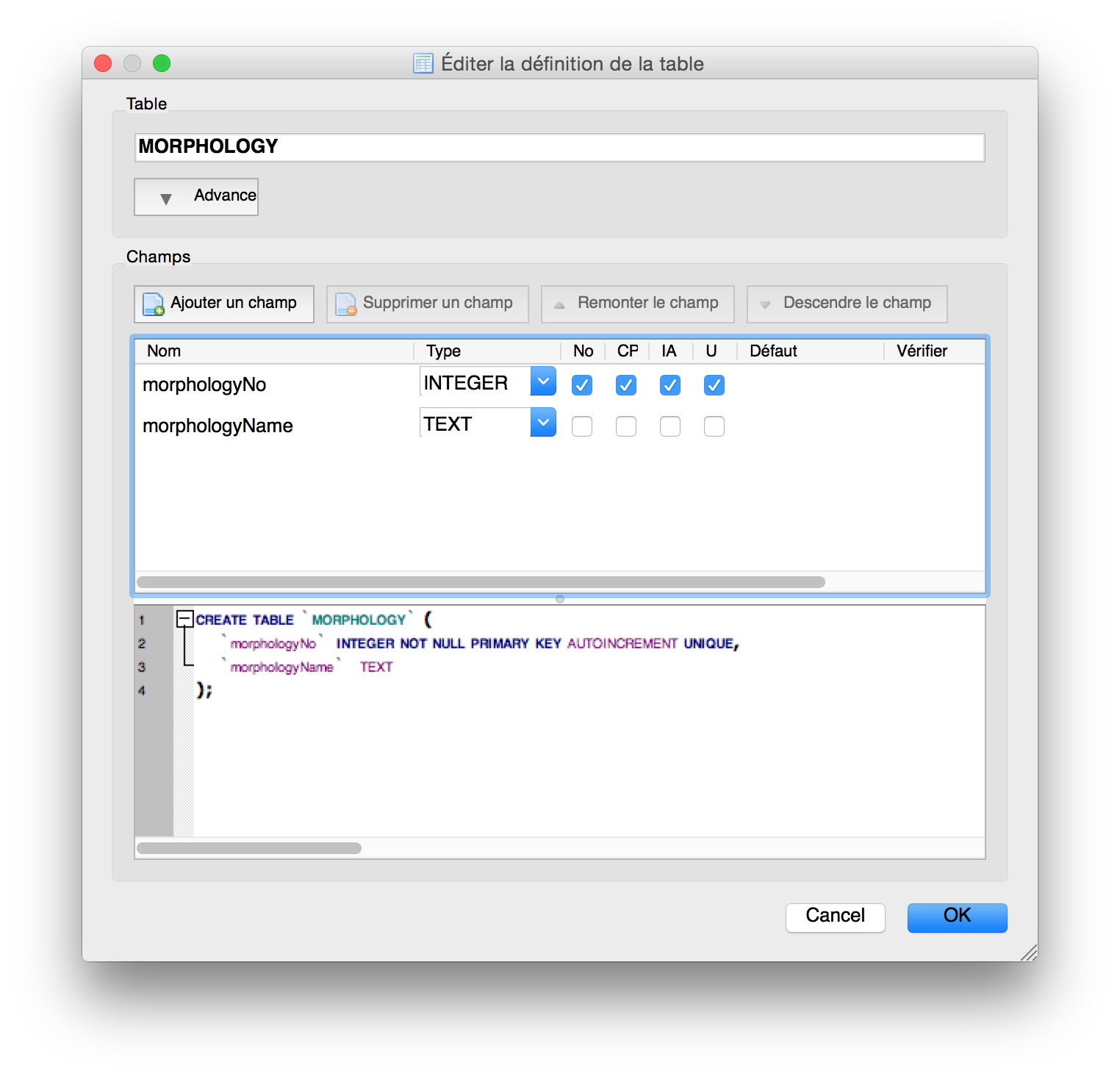 Figure 5. Creating the MORPHOLOGY table.
Figure 5. Creating the MORPHOLOGY table.
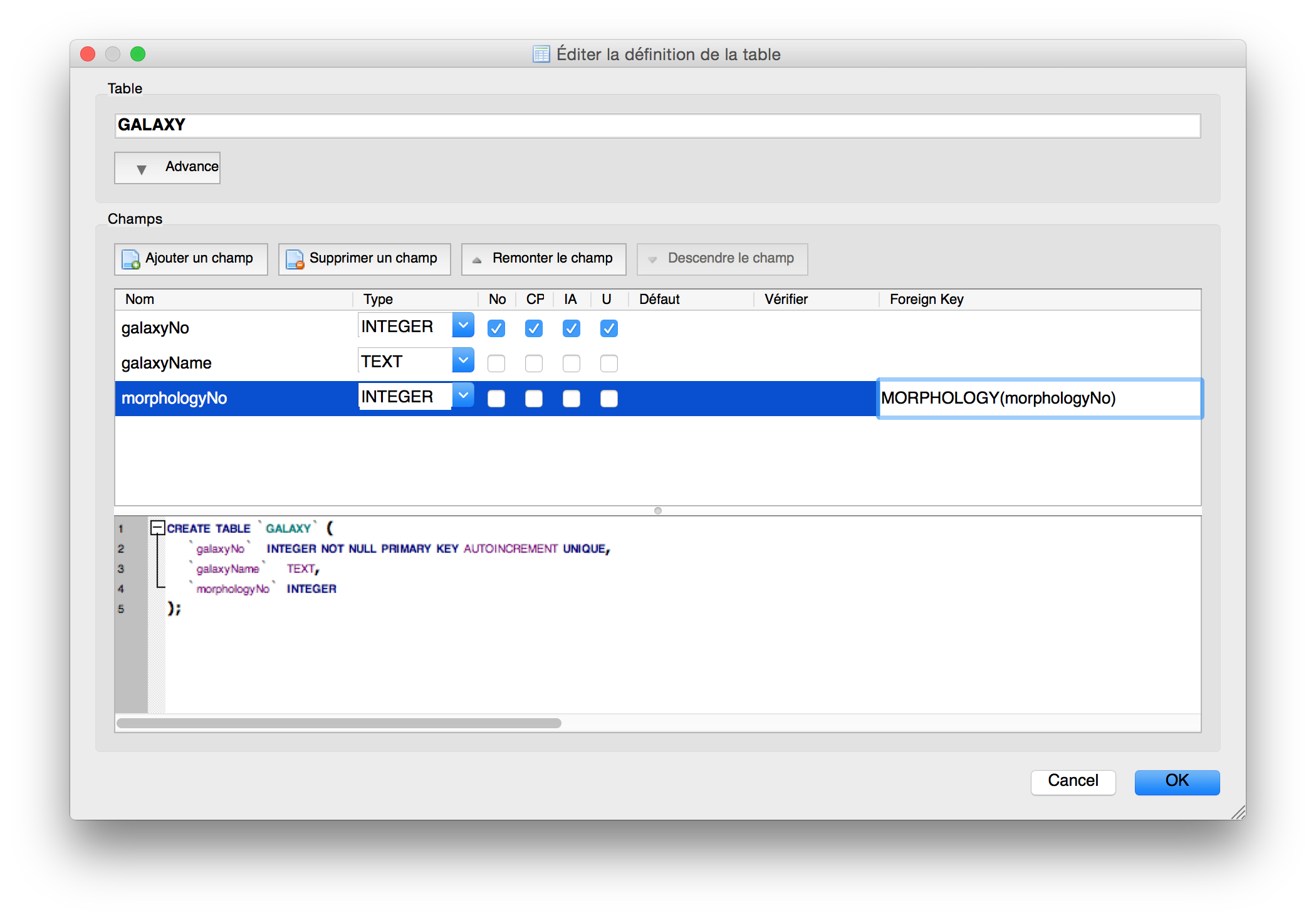 Figure 6. Creating the GALAXY table.
Figure 6. Creating the GALAXY table.
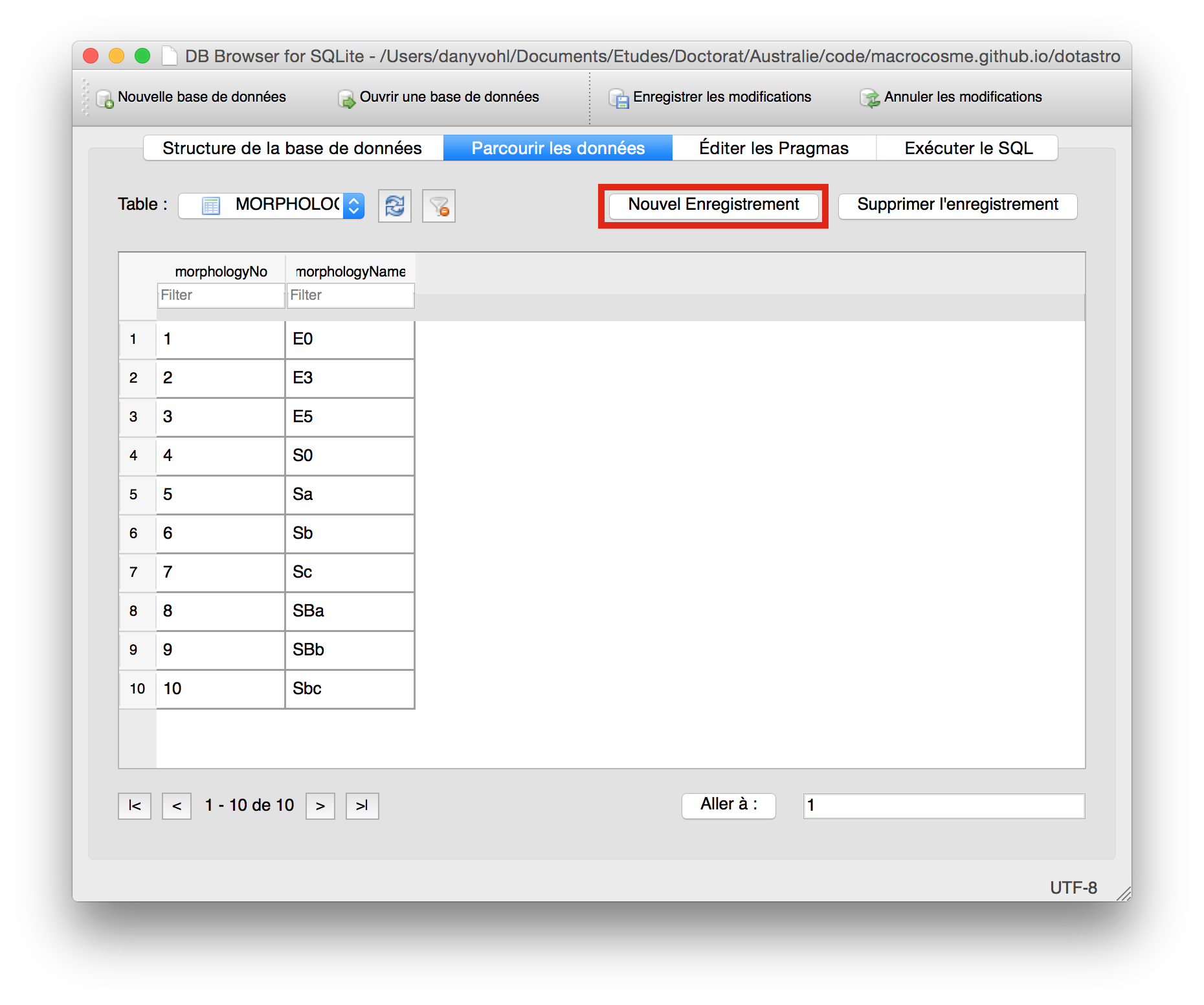 Figure 7. Manually adding data to the MORPHOLOGY table.
Figure 7. Manually adding data to the MORPHOLOGY table.
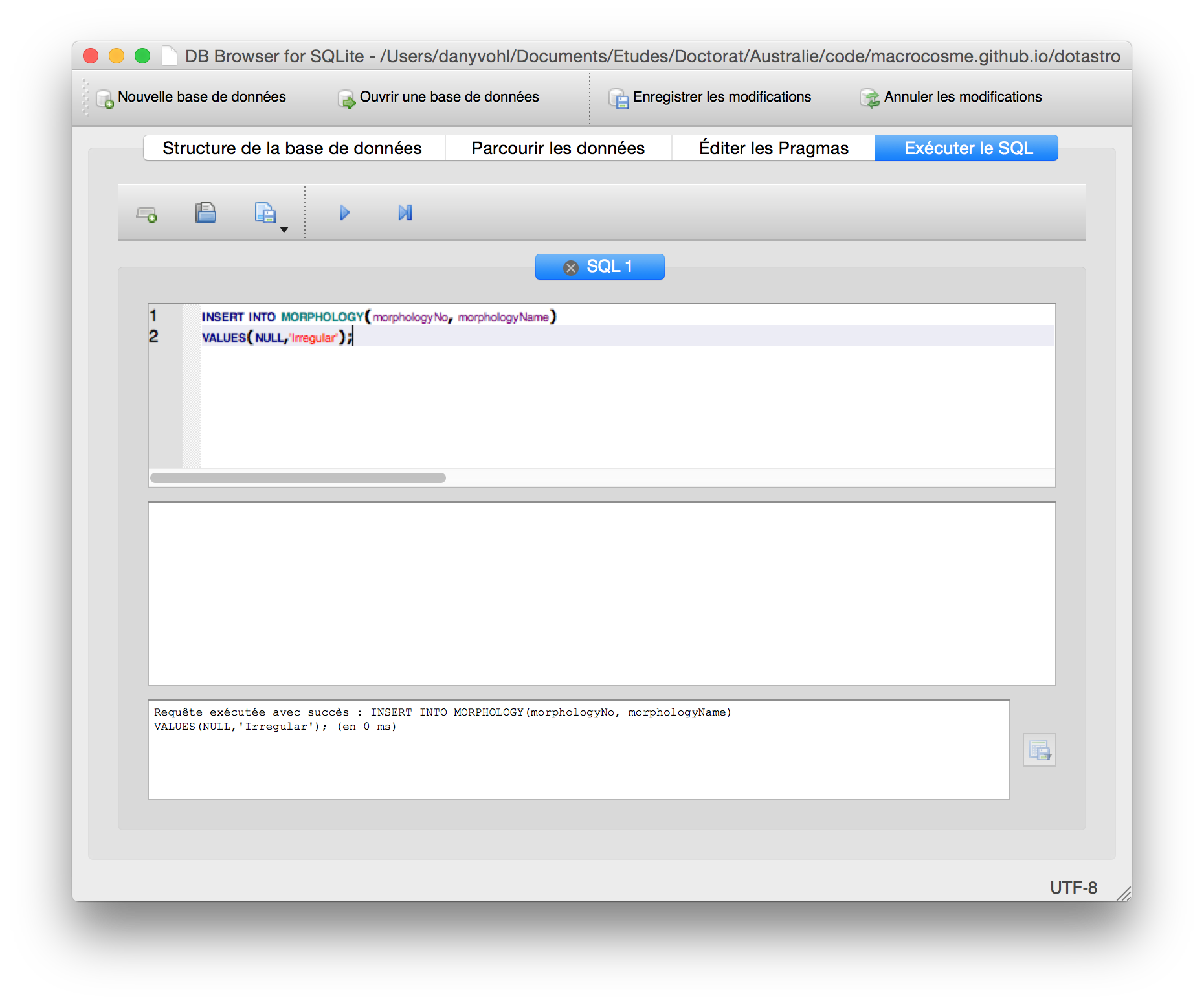 Figure 8. Query result.
Figure 8. Query result.
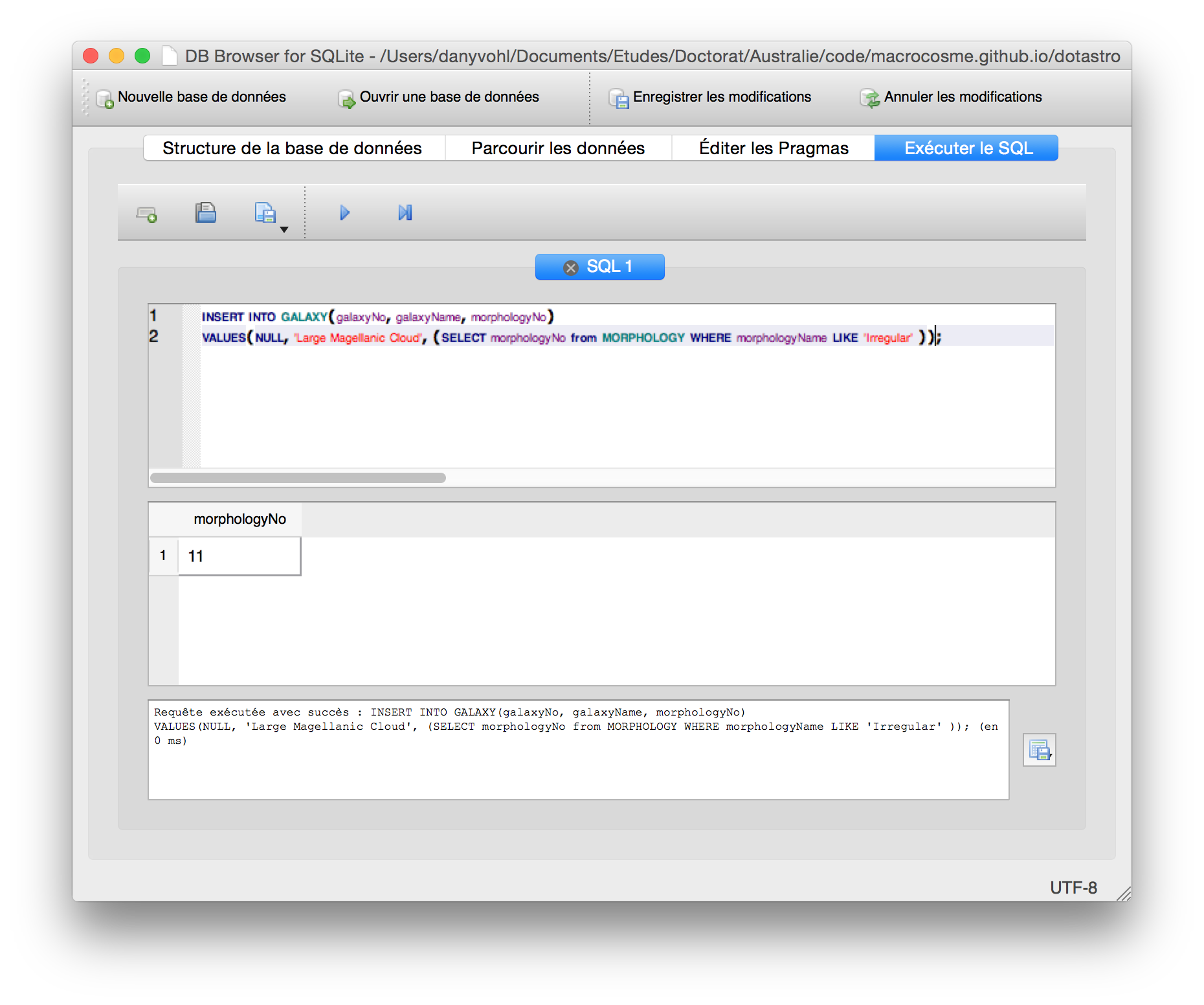 Figure 9. Query result #2.
Figure 9. Query result #2.
 Figure 10. The Large Magellanic Cloud (source: fromquarkstoquasars.com).
Figure 10. The Large Magellanic Cloud (source: fromquarkstoquasars.com).
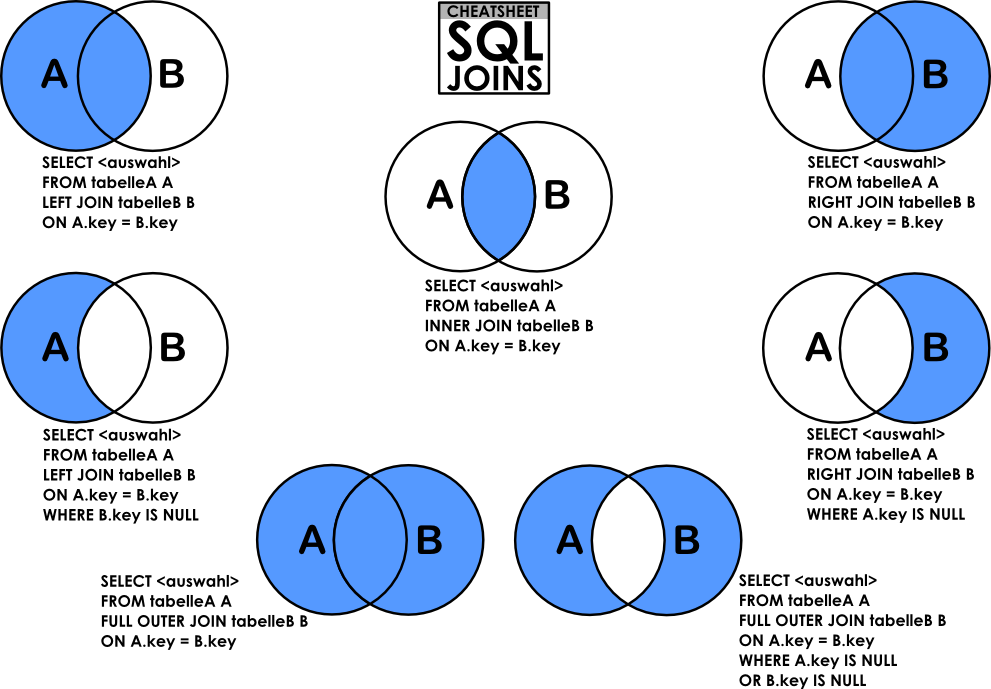 Figure 11. Venn diagrams of the different types of JOIN (source: dsin.files.wordpress.com).
Figure 11. Venn diagrams of the different types of JOIN (source: dsin.files.wordpress.com).
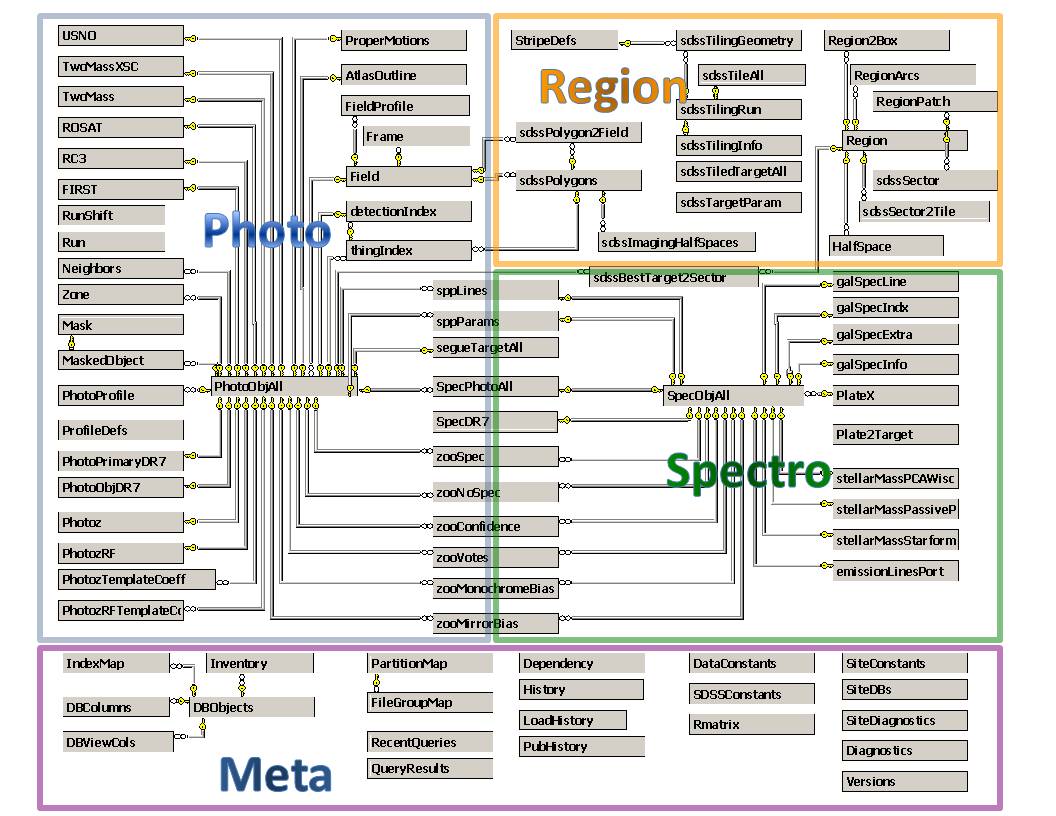 Figure 12. SDSS DR12 Database schema (source: http://skyserver.sdss.org/dr12).
Figure 12. SDSS DR12 Database schema (source: http://skyserver.sdss.org/dr12).
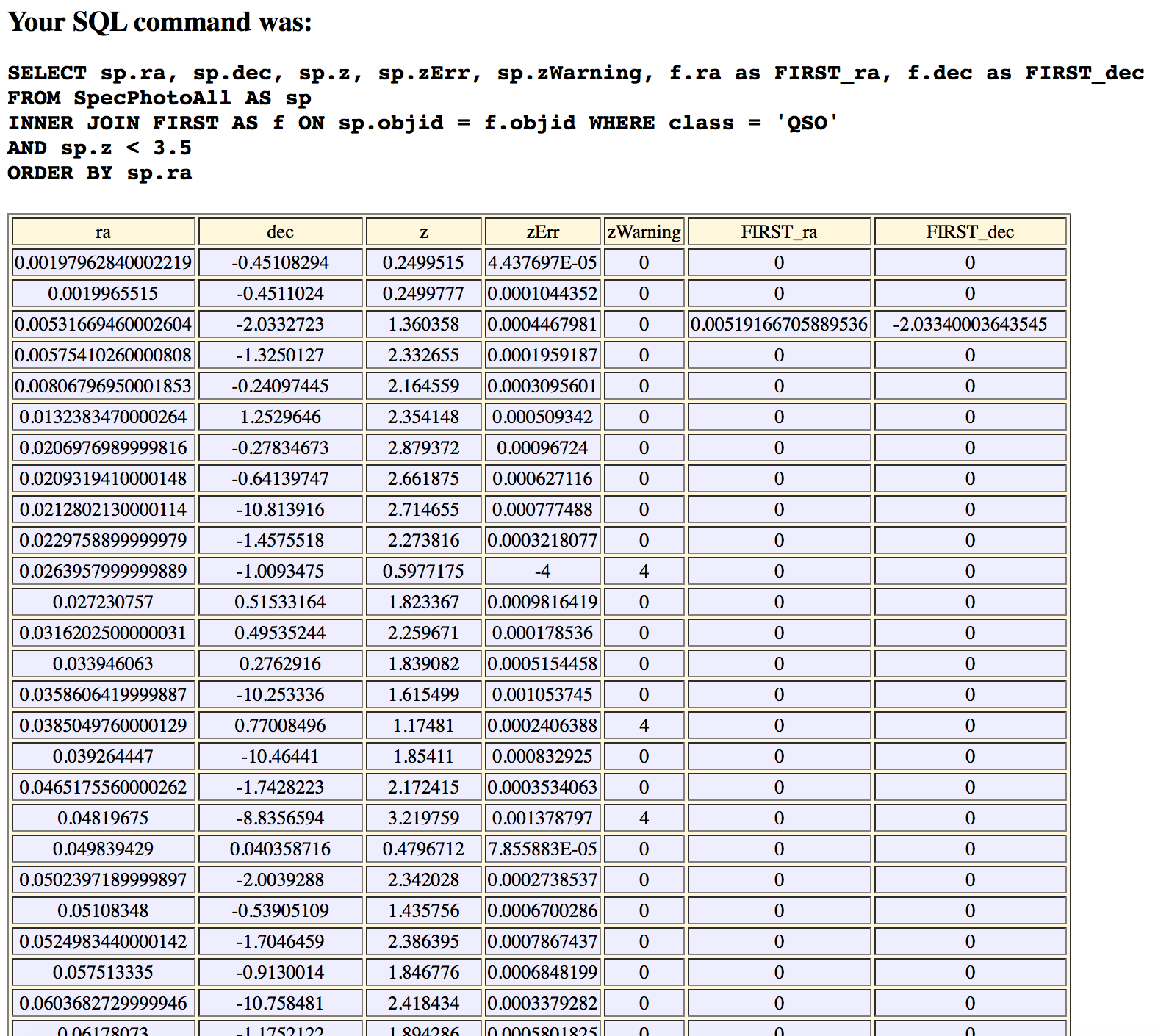 Figure 13. Query result.
Figure 13. Query result.